
Background
A couple of weeks back, I was discussing with a friend of mine, on the topic of training materials on Apache Spark, available online. Of the couple of sites that I mentioned, the hadoop tutorial from Hortonworks, came up. This was primarily because I liked the way they organized the content: it was clearly meant for encouraging newcomers to try things hands-on, banishing the fear that accompanies first-timers. Some people have pointed out me that some of those were a bit dumbed down in content (not so much in form), but I disagree. If the main purpose of a tutorial is to attract and engage more and more people, a tutorial maker should be ready to err on the side of dilution if necessary, rather than to make it too impressive to approach. But, this is a digression.
Because of late, I have fallen unhesitatingly and unequivocally for Apache Flink, I have revisited one of the tutorials on the Hortonworks site to see how quickly I can make an equivalent tutorial using Apache Flink. The objective is to prepare a quick tutorial for Apache Flink which, one can always compare with the solution given at Hortonworks site, whenever necessary. It helps to find equivalence between established wisdom and exploratory urge, when learning something new. So, I believe.
Following Hortonworks, with some difference
I have chosen the particular tutorial here:
This deals with a set of Sensor data. The objective to is to refine the input dataset and then visualize it quickly. The input data comprises of two CSV files. Hortonworks’ tutorial uses Hive, Microsoft Excel and Apache Zeppelin - all running inside the Hortownworks’ Sandbox - to refine and visualize the data.
In my case, I have used Apache Flink in LocalExecutionMode for refinement. Because I don’t have the Sandbox and I am not a Microsoft Windows user, I have chosen to use Google Docs (spreadsheet), Google Map and Apache Zeppelin for the job at hand. This arrangement, keeps the equivalence between Hortonworks’ tutorial piece and mine.
Gist of the application we are implementing
5 different models of HVAC devices for measuring temperatures, have been installed in 20 large buildings across a number of countries. The data collected from these sensors include the actual temperature recorded and ideal temperature to be maintained. We want to analyze how frequently, has the actual temperature, deviated from the ideal temperature to be maintained (hotter and colder) and how the devices have performed.
Description of input data
The application makes use of two different sources of input:
- Buildings.csv:
This file contains static information about the buildings where the HVAC devices are fitted, viz,
- Building’s Identifier
- Building’s Manager’s identifier
- Building’s Age (how old is it)
- Identifier of the HVAC device
- Country where the building is located
- HVAC.csv:
This file contains the actual device readings and carries the fields
- Date of reading
- Time of reading
- Actual temperature read at the time
- Expected temperature to be maintained
- System Identifier
- System’s age
- Building’s identifier
Records from these two files are read into two case classes:
case class HVACData(
dateOfReading: String, timeOfReading: String ,actualTemp: Int,targetTemp: Int,
systemID: Int, systemAge: Int, buildingID: Int)
|
case class BuildingInformation(buildingID: Int, buildingManager: String, buildingAge: Int, productID: String, country: String)
|
Objective of the exercise
It is important to understand what we want to do.
We want to find out that out of the many readings that ‘HVAC.csv’ presents, which readings indicate that temperature was not maintained properly. If the difference between the temperature recorded and expected is beyond the permissible range of 5 degrees (either more or less), then those readings attract our attention. The residents of those buildings didn’t enjoy optimum temperatures throughout (which perhaps the device manufacturers promised).
From readings having such anomalous temperature figures, we want to find out
- Which countries do those affected buildings belong to
- Which kind of devices are most prone to show such behaviour
In order to make it easy for us to explore the above-mentioned two parameters, we need to ‘refine’ the data. In other words, we need to create new readings carrying only those pieces of information that we need (either by copying from the input or computing on the fly). The following shows the case class that is meant for the purpose:
case class EnhancedHVACTempReading(
buildingID: Int, rangeOfTemp: String, extremeIndicator: Int,
country: String, productID: String,buildingAge: Int,
buildingManager: String)
|
Just a note: actually, for our exercise, we don’t really need ‘buildingAge’ and ‘buildingManager’ fields. I have kept them here because I want to remain faithful to the original tutorial by Hortonworks.
With these three pieces of data structure, we can begin.
How do we process using Flink
The key thing is to spot the refinement: we want to create new readings using records from both the files, whenever the value of buildingID is common. In other words, we join the readings on this buildingID field.
This application is apt to be a batch process. Both the sets of input are final and ready. One of the inputs (buildings.csv) contains records which are static. For the run of the application, they are very unlikely to change; certainly not every minute.
We have to provide this static, largely unchanging data as read-only source of reference. Flink allows us to create broadcast data-set. Such a set is made available to all the partitions by Flink’s runtime. In our case, the number of buildings is finite and not unmanageably large. Therefore, it qualifies to be considered for broadcasting across partitions.
Creation of EnhancedHVACTempReading is just another transformation using Flink’s operators. For every HVAC reading, we consult the Building data set (made available through broadcast) and if the building’s ID is common, we create a corresponding EnhancedHVACTempReading:
val joinedBuildingHvacReadings = hvacDataSetFromFile
.map(new HVACToBuildingMapper)
.withBroadcastSet(buildingsBroadcastSet,"buildingData")
|
We pass an instance of HVACToBuildingMapper class to the map() function. This class holds the logic of joining two sets of records based on the building’s identifier:
class HVACToBuildingMapper
extends RichMapFunction [HVACData,EnhancedHVACTempReading] {
// ..
}
|
As is probably obvious, the call to withBroadcastSet(buildingsBroadcastSet,"buildingData") achieves the effect of broadcasting. The variable buildingsBroadcastSet contains information about each building held in the form of case class BuildingInformation.
How is the refinement implemented?
The class HVACToBuildingMapper is responsible for the act of refinement. Let’s recall that a refined record is represented by an instance of EnhancedHVACTempReading class. In order to create such an instance,
- We need to know the country where the building is located. This is available in buildingsBroadcastSet.
- We need to determine if the difference between actual and ideal temperatures crossed the acceptable limit (and use the outcome for instantiation). This piece of logic is run for every HVACData record.
Here’s the anatomy of the class HVACToBuildingMapper:
override def open(configuration: Configuration): Unit = {
allBuildingDetails =
getRuntimeContext
.getBroadcastVariableWithInitializer(
"buildingData",
new BroadcastVariableInitializer
[BuildingInformation,Map[Int,BuildingInformation]] {
def initializeBroadcastVariable
(valuesPushed:java.lang.Iterable[BuildingInformation]):
Map[Int,BuildingInformation] = {
valuesPushed
.asScala
.toList
.map(nextBuilding => (nextBuilding.buildingID,nextBuilding))
.toMap
}
}
)
}
|
This function, open(), is called by Flink once per partition. If you look a bit closely, you can see that it is creating a Map of buildingID and BuildingInformation and storing that in a variable named allBuildingDetails.
override def map(nextReading: HVACData): EnhancedHVACTempReading = {
val buildingDetails =
allBuildingDetails.getOrElse(
nextReading.buildingID,UndefinedBuildingInformation
)
val difference = nextReading.targetTemp - nextReading.actualTemp
val (rangeOfTempRecorded,isExtremeTempRecorded) =
// Permissible deviation of temperatures is 5 degrees
if (difference > 5 ) ("COLD", 1)
else if (difference < 5) ("HOT", 1)
else ("NORMAL",0)
EnhancedHVACTempReading(
nextReading.buildingID,
rangeOfTempRecorded,
isExtremeTempRecorded,
buildingDetails.country,
buildingDetails.productID,
buildingDetails.buildingAge,
buildingDetails.buildingManager
)
}
}
|
For every record of HVAC being transformed, the map() function is called. We extract the BuildingInformation corresponding to the buildingID that the HVAC record brings in. Then, we determine if the difference between temperatures is within the allowed range or not and collect the outcome as a pair. For every "HOT" and "COLD" range, the extreme temperature is considered to be 1. Finally, we create an instance of EnhancedHVACTempReading as a result of transformation.
We transform the input data twice: (a) extremeTemperaturesRecordedByCountry and (b) hvacDevicePerformance:
val extremeTemperaturesRecordedByCountry = joinedBuildingHvacReadings
.filter(reading =>
reading.rangeOfTemp == "HOT" || reading.rangeOfTemp == "COLD"
)
.map(e => (e.country, 1)) // attaching an unit count to every record
.groupBy(0)
.sum(1)
.writeAsCsv("./countrywiseTempRange.csv")
|
And
val hvacDevicePerformance =
joinedBuildingHvacReadings
.map(reading => (reading.productID,reading.extremeIndicator))
.filter(e => (e._2 == 1)) // 1 == Extreme Temperature observed
.map(e => (e._1,1)) // attaching a unit count to every record
.groupBy(0) // ProductID
.sum(1)
.writeAsCsv("./hvacDevicePerformance.csv") |
When we run the application, the output CSV files are created as expected.
4 files are created under each directory because my laptop has 4 cores - and hence, by default, 4 threads - that Flink uses as partitions when I run the application in the local execution mode.
What about the contents of these files. Let’s take a look:
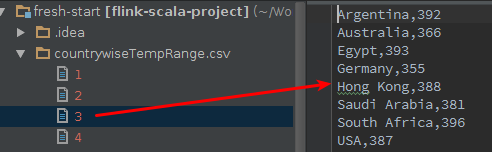
And

As for the performances of the devices, here’s what we get:

And
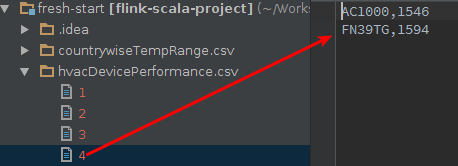
In a real application, all these output files will be created as multiple file (blocks) in HDFS, perhaps. Here, they all reside in my laptop’s local Linux Ext4 file system. When using them for the purpose of reporting, I simply concatenate them using a bash command.
Visualization
In the Hortonwork’s tutorial, Microsoft Excel’s Power features are used to plot the countries in a geographical map. In my case, I transported the concatenated CSV files to my Google Drive. Then, using the the facility to create geographical maps in Google Spreadsheet (here and here, if you are interested), I have plotted the countries across the world, along with the deviations from expected temperatures:
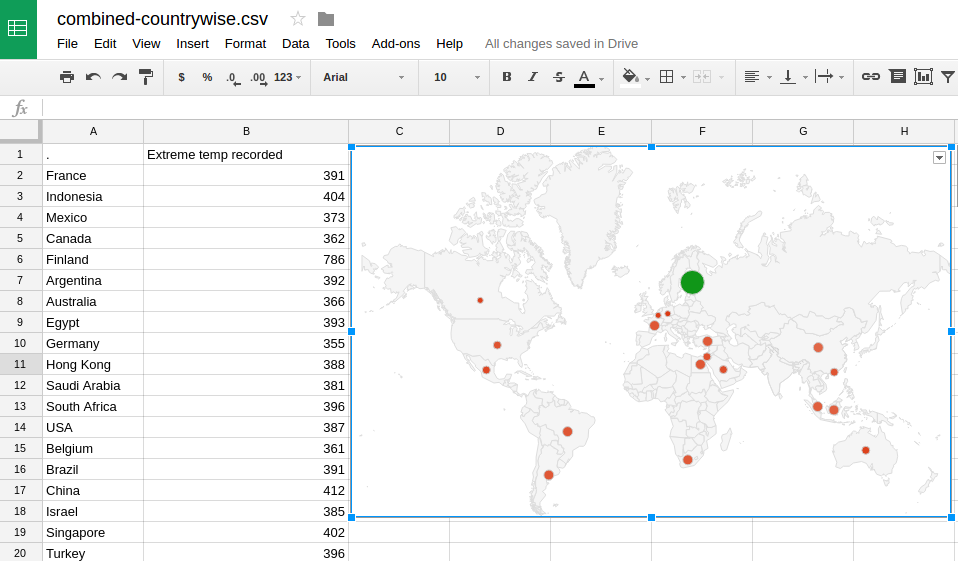
Clearly, most of the deviations have been reported from Finland!
Also, just like shown in the Hortonwork’s tutorial, I plot the performance of each of the HVAC devices using Google Spreadsheet:
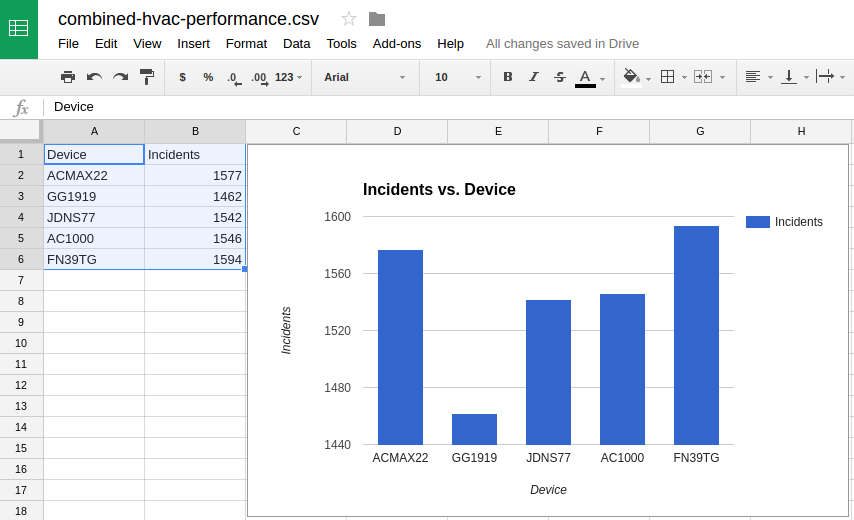
Hmm.. the Device(GG1919) has performed the best so far and Device(FN39TG) requires to be inspected, as early as possible.
This is really a toy application, but I intended to demonstrate how data can be broadcast to multiple partitions, especially for a lookup functionality. If a bunch of data is relatively unchanged and is primarily used as a reference during transformations, making it available through broadcast mechanism is one of most appropriate solutions that Flink offers.
All comments and critiques are welcome. I would love to hear if there is any gap in my understanding and where.
Great stuff, thanks for sharing!
ReplyDeleteGreat article !! Congratulations! Thank you for sharing your knowledge and experience!
ReplyDeleteNice tutorial information about sensor data.
ReplyDeleteBig Data Analytics Services
Big Data Services