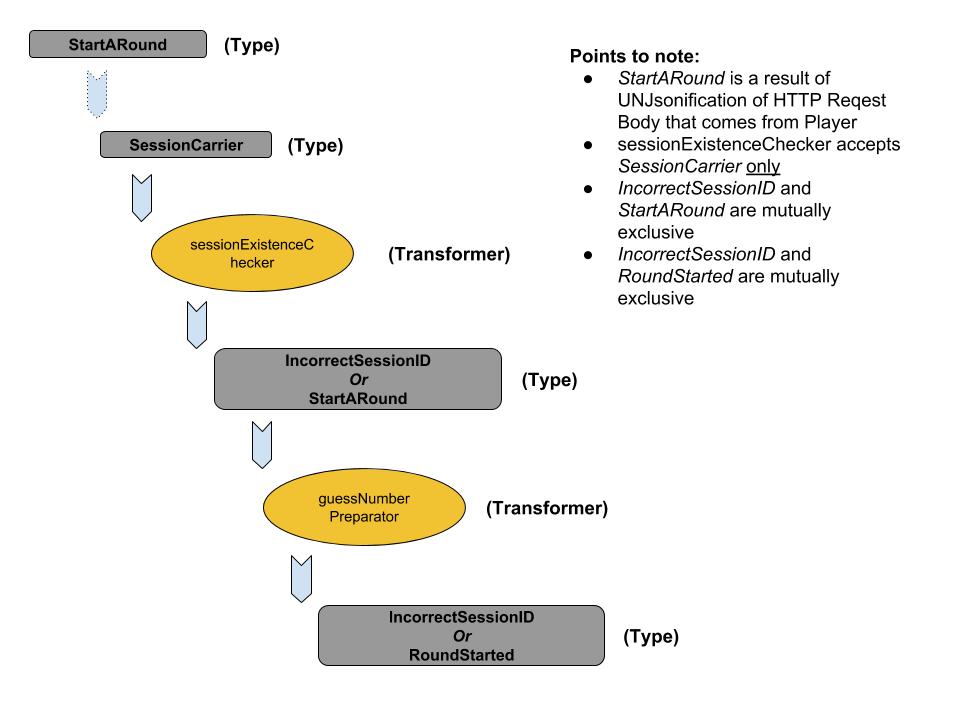
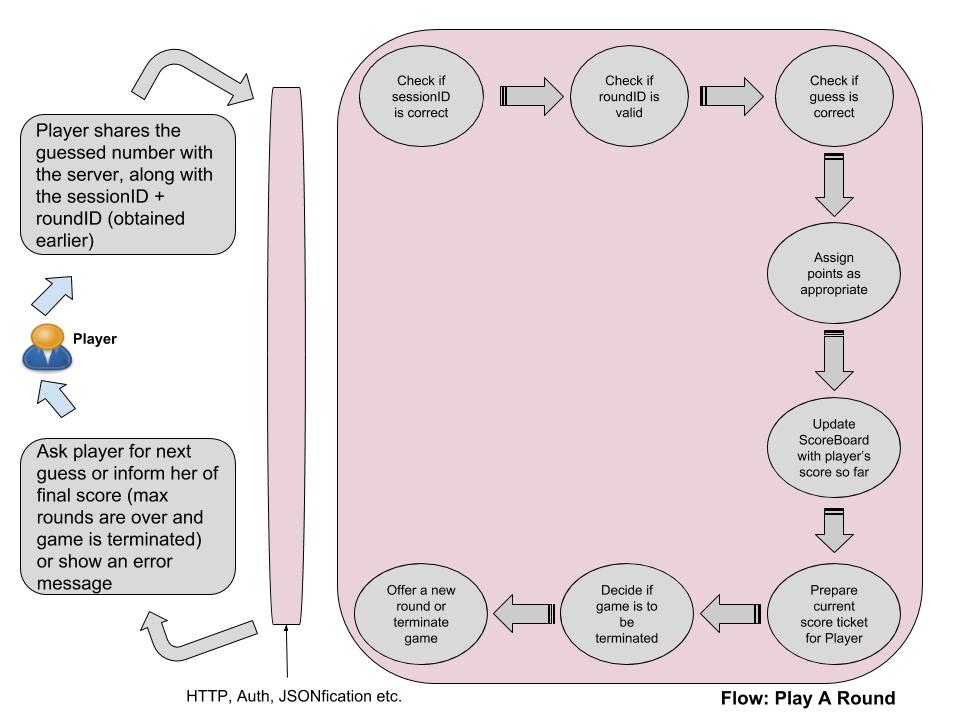
As a consulting CTO/Engineering head for small-sized and medium-sized software product firms for about one and half a decade, often times I am asked this question by the main stakeholders of current and potential clients: why do I need your service? What can you do, that can benefit us?
It is an obvious question to ask. It is a fair question too. Over years, I have tried to answer this question to the best of my ability and intent. It will be a lie if I say that every time, my explanations drove home the point, as concisely as one expected. However, a theme underpinned my answers, every time. This write-up is an elaboration of that theme.
It helps to have someone as a sounding board for all things technical, behind your product
As your idea is taking shape or your offering is getting newer features (thereby bringing in new customers, you don’t want to lose the momentum. Catering to customers’ demands, adding features to the product, positioning it for newer market segments: all these are important for you and your Product Management team. However, the software stack that is going to lie underneath all these, has to support the offering, all along. Some level of plumbing is necessary now and cheap; the rest should be built as the direction of the product becomes clearer with the journey. A CTO can hear your plans, co-visualize the product alongside you, align your vision with trends of technology and outline for you technical underpinning that must evolve, you will have a much better view of cost of building what you want to build, the time it is going to take and the risks and benefits that alternatives offer.
Your Product Management team must be heard well and told clearly
Your Product Managers have ideas. They are quite enthusiastic about those. They would want these ideas to be implemented/realized as early as possible. However, they look for assurances from the engineering/technical team about the feasibility. The engineering team has to know really, really well what needs to be built, in order for those ideas to be materialized. An experienced CTO/Engineering Head can bridge this gap effectively and quickly. One cannot emphasize the importance of this act of elaboration: the correctness and completeness of the next several milestones of the product depend overwhelmingly on how well the boundaries are drawn and innards are sketched. Some times, the CTO may insist on restricting some feature temporarily so that subsequent features can be rolled out much faster. Some other times, the Engineering head may advise to fold two seemingly unconnected features together because of very beneficial reuse of components. A CTO can be the perfect interlocutor and devil’s advocate who talks straight, all for your benefit.
The future versions of the software requires deep and wide considerations
First version of the product came into being primarily because the first customers had to be acquired. Because of value your product continued to put forward, next few customers came in too. Now, the expectations of these customers — and of many potential future customers — are weighing heavily in your plans and in your software. The second version has to be built right, because the next phase is not only of growth but also of retention. The technical choices and decisions that your engineering team faces, turns quite challenging as the product begins to cater to variety of customers. The overall architecture may need a revisit. The non-functional requirements may crystallize and pose questions about the current technical structure. Perhaps, several proof-of-concept exercises become necessary. Your engineering team finds themselves in a flux. The steady and reassuring presence of a CTO can be immense help in situations like this.
Accidental complexities of software have to be dealt with
The primary features of the product you build, don’t necessarily depend on the complexity that the software begets or is infused with. You may begin with a browser-based UI but soon decide to move to native mobile apps. The code-bases increase. The areas of expertise required, increase. In effect, the whole of the development pipeline is affected, one way or the other. Business may demand a move to a cloud provider. The operational aspects spring up. The laws of the land may demand special actions to ensure privacy of your customers. All these cost money, time and effort. You will need someone to think and plan through these not-so-straightforward aspects. Someone must understand what the engineering team is facing and help align their preparatory or mitigative steps that gain confidence the Product Management team. As the accidental complexity grows, so do the need of specialized expertise in your engineering team. Your CTO will ensure that right teams are given the right tasks and establish appropriate engineering best practices. By avoiding mistakes she has learnt through her experiences, she can prevent cost of release and rework (this can be a substantial cost).
Your engineering team is your asset too; nurture the members and environment
Collectively, your engineering team carries a picture of the product: the various inputs and outputs, their formats, the points of integration with other 3rd party software, schema of the data storage, boundaries of primary business functions and their representation in executable form etc. They want the software they have built, to be used extensively by the intended users, both internal and external. That is the source of their **self-actualization**. An enthusiastic and expert team can, not only bring to fruition newer features smoothly, but also attract equally enthusiastic and expert staff from outside. Put differently, in order for the product to grow and meet expectations — speedily and timely — your engineering team has to be at its best. And, which challenges do they solve and how, go a long way to induce other great software technologists from outside to your organisation. A CTO can bring about the passion and commitment to your engineering team and help build a culture that stands your organisation in good stead. In a larger sense, such a team is one of the main ingredients of the world-class product that you build.
By hiring a CTO/Engineering Head — even in advisory or consulting positions — you and your stakeholders can be highly benefited. By having a clear understanding of the business and its future as well as a fantastic grasp of technology trends, with hands-on knowledge as necessary, a CTO can anticipate directions that your business is going to take, take preparatory measures on behalf of your technology team and help your business stay ahead of the curve, as it were. In the process, she also prevent not-so-obvious mistakes your engineers are likely to make and save you from unnecessary costs.